La implementación exitosa de la inteligencia artificial (IA) en los negocios requiere una comprensión profunda del proceso de Data Science y Machine Learning (ML). En esta guía, exploraremos qué es un modelo de ML, cómo se construye, se entrena y se valida, proporcionando una visión valiosa para aquellos profesionales que están dando sus primeros pasos en la aplicación de la IA en entornos empresariales.
Definición de un Modelo Matemático:
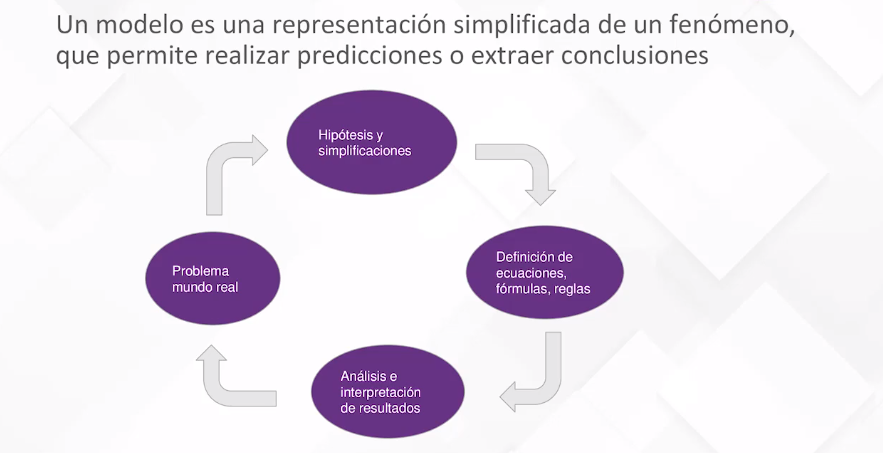
Comencemos por comprender qué es un modelo en el contexto de ML. Un modelo matemático es una representación simplificada de un fenómeno que permite realizar predicciones o extraer conclusiones. A lo largo de la historia, se han desarrollado numerosos modelos, siguiendo un proceso iterativo de observación del mundo real, formulación de hipótesis, definición de ecuaciones y reglas, y ajuste continuo para lograr la máxima precisión. Un ejemplo clásico es la teoría de la gravedad de Newton, que se derivó observando la caída de una manzana.
Aplicación en Machine Learning:
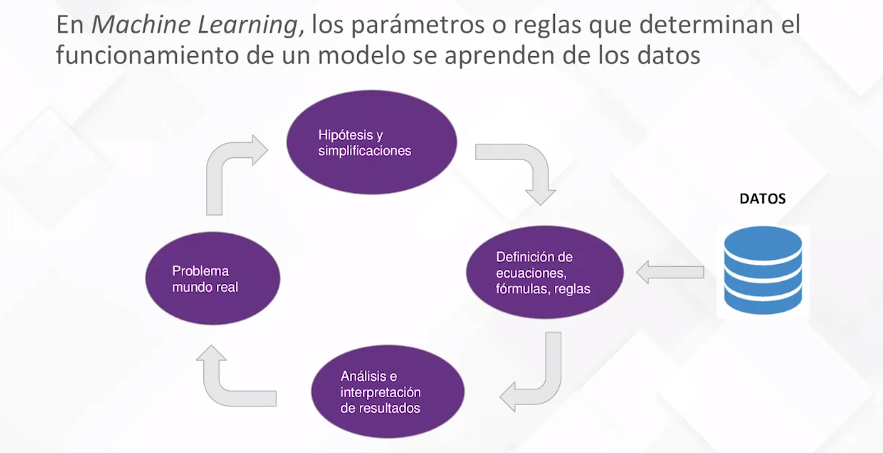
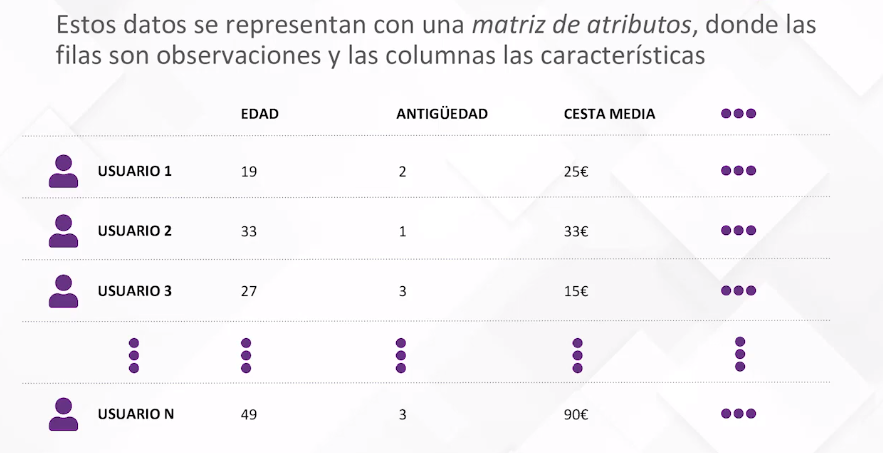
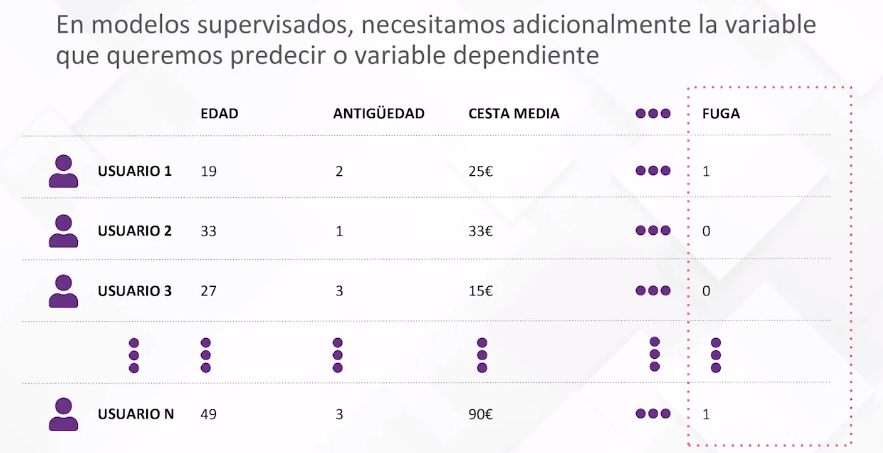
En el contexto de ML, este proceso se inicia con datos, siendo estos el conductor fundamental para que el modelo funcione. La generación de un modelo matemático implica la creación de reglas, ecuaciones o fórmulas a partir de los datos. La representación típica de estos datos es a través de una matriz de atributos, donde cada observación se presenta como una fila y las variables informativas como columnas. Por ejemplo, para caracterizar clientes de una empresa, las filas podrían representar usuarios, y las columnas, características como edad, antigüedad y cesta media de compra.
Modelo Supervisado y Variable Objetivo:
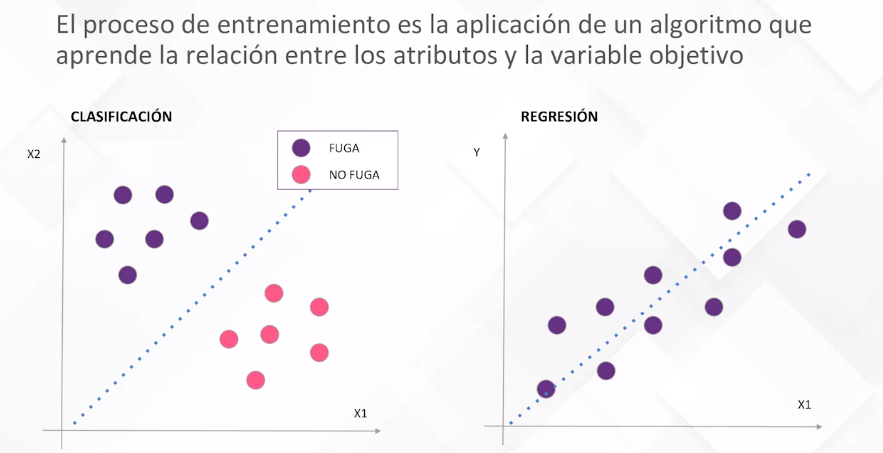
En un modelo supervisado, además de la matriz de atributos, necesitamos una variable objetivo que queremos predecir. Por ejemplo, en la clasificación de clientes de una empresa de telecomunicaciones, la variable objetivo podría ser el riesgo de fuga. El proceso de entrenamiento implica que el algoritmo de ML aprenda la relación entre los atributos y la variable objetivo, distinguiendo entre clasificación y regresión según la naturaleza de la predicción.
Ejemplos de Modelos y Visualización:
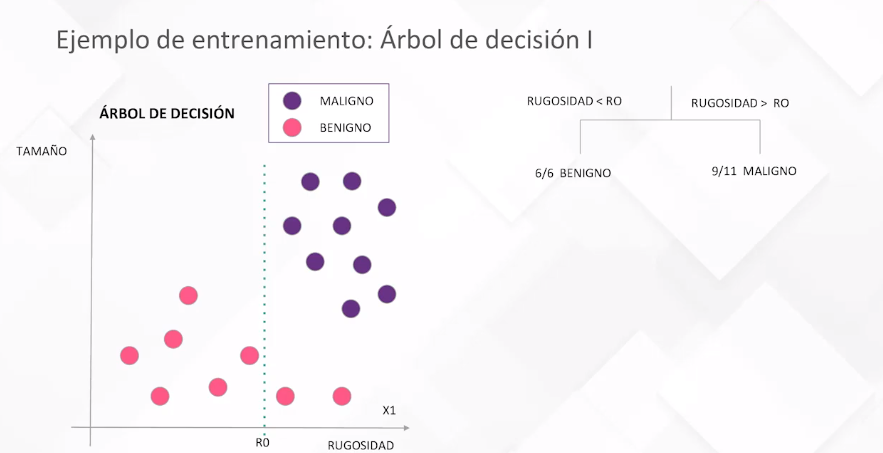
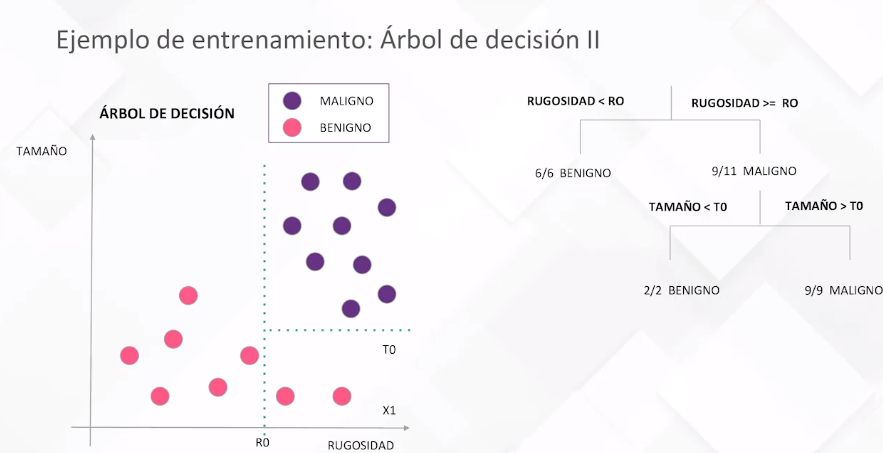
Diferentes algoritmos, como regresiones lineales, árboles de decisión, redes neuronales, entre otros, operan de manera similar, ajustando parámetros internos durante el entrenamiento para adaptarse a los datos. Se presentan ejemplos visuales de modelos lineales, regresiones logísticas y árboles de decisión para ilustrar cómo estos definen fronteras de decisión o líneas para predecir resultados.
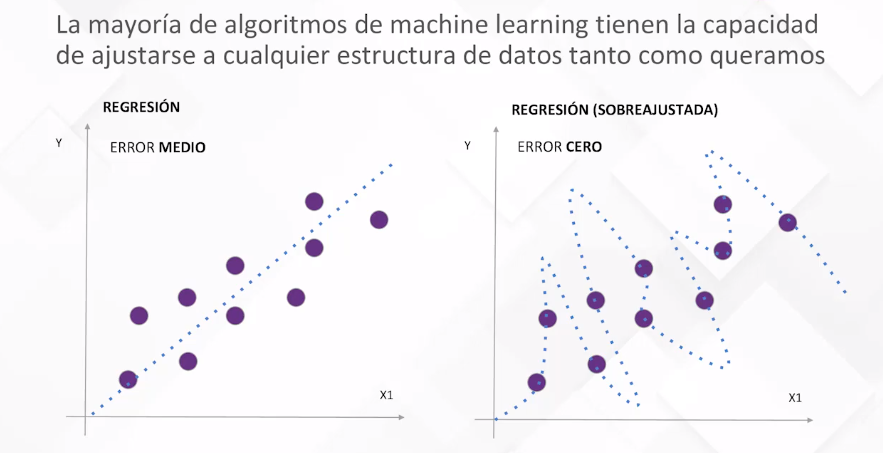
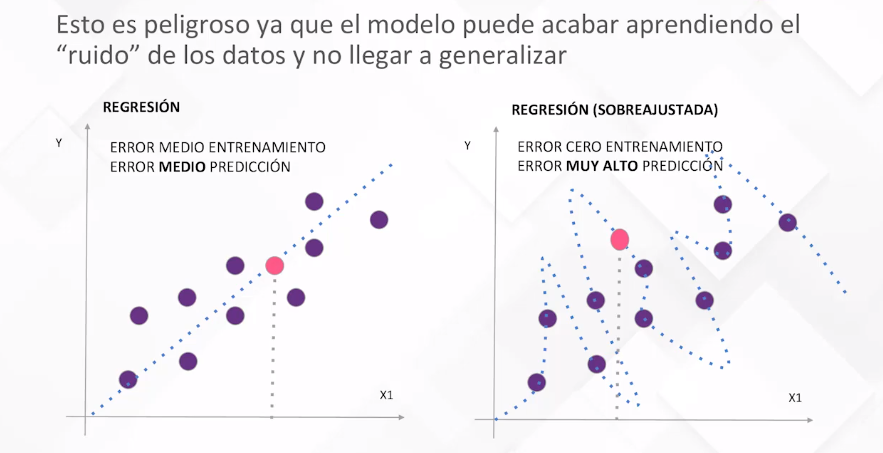
Previniendo el Sobreajuste:
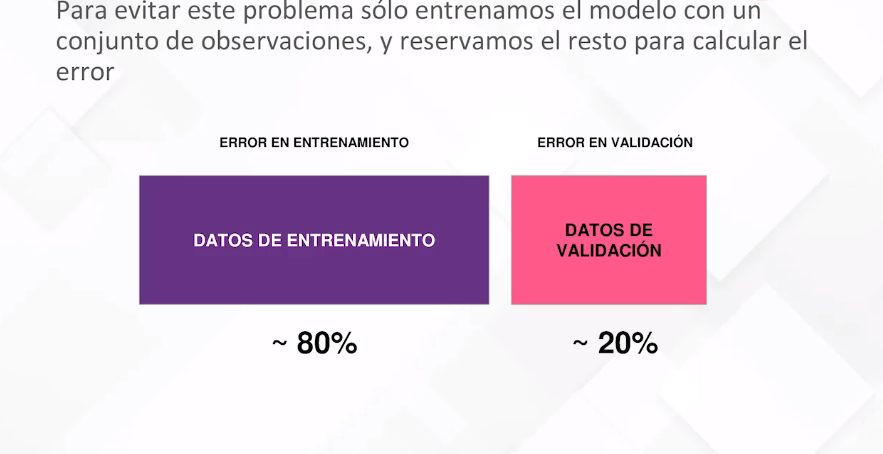
Un desafío crucial en la creación de modelos es evitar el sobreajuste, donde el modelo se adapta demasiado a los datos de entrenamiento, aprendiendo incluso el ruido presente. La solución radica en dividir el conjunto de datos en entrenamiento y validación. El objetivo principal es optimizar el error en el conjunto de validación en lugar del conjunto de entrenamiento.
Selección de Parámetros y Validación:
La selección de parámetros, como la profundidad del árbol en un modelo de árbol de decisión, es esencial. Se ilustra cómo evaluar el rendimiento del modelo en función de parámetros específicos, eligiendo aquellos que minimizan el error de validación y evitan el sobreajuste.
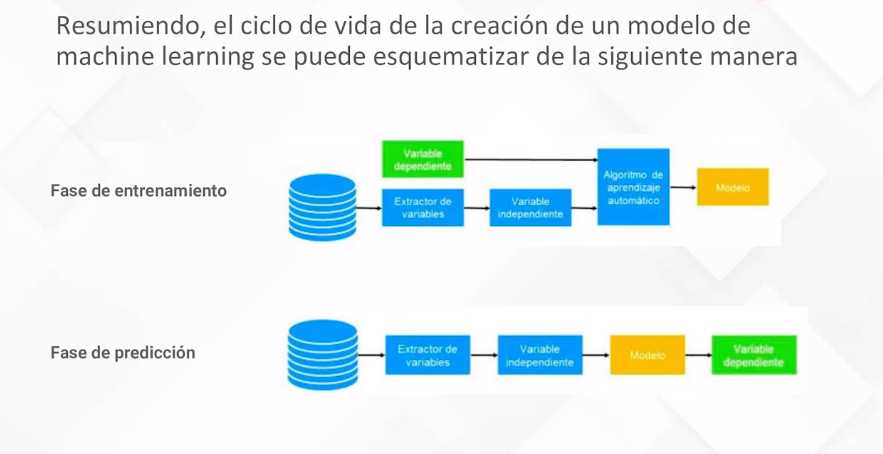
Ciclo de Vida del Modelo:
Finalmente, se esquematiza el ciclo de vida de la creación de un modelo, desde la fase de entrenamiento hasta la aplicación del modelo en nuevos datos para hacer predicciones en la realidad.
EJEMPLO :
| Paso | Descripción |
|---|---|
| 1. | La empresa de telecomunicaciones busca reducir la pérdida de clientes. |
| 2. | Se formula la hipótesis de que la pérdida de clientes está relacionada con la antigüedad, tipo de contrato, y frecuencia de uso, entre otros factores. |
| 3. | Creación de modelos matemáticos con ecuaciones o reglas para representar la relación entre atributos y la probabilidad de fuga. |
| 4. | Construcción de una matriz de atributos con datos como antigüedad, tipo de contrato, frecuencia de uso, etc. |
| 5. | Uso de algoritmos de Machine Learning para aprender la relación entre atributos y la probabilidad de fuga. |
| 6. | Variable objetivo: Riesgo de fuga del cliente (Sí/No). Modelo supervisado aprende a predecir la fuga basándose en datos históricos. |
| 7. | Entrenamiento del modelo con un conjunto de datos históricos para que aprenda patrones de fuga. |
| 8. | División del conjunto de datos en entrenamiento (80%) y validación (20%) para prevenir el sobreajuste. |
| 9. | Optimización de parámetros como la profundidad del árbol de decisión o la tasa de aprendizaje. |
| 10. | Ciclo de vida del modelo: Fase de entrenamiento y fase de predicción. |
| 11. | Utilización del modelo para predecir la probabilidad de fuga de nuevos clientes. |
| 12. | Implementación de estrategias de retención basadas en las predicciones del modelo. |
Esta tabla proporciona una estructura clara de los pasos en el ejemplo práctico de predicción de fuga de clientes en una empresa de telecomunicaciones mediante Machine Learning.
En resumen, el proceso de Data Science y Machine Learning es un viaje desde la observación de datos hasta la creación de modelos predictivos. La comprensión de la importancia de la validación y la prevención del sobreajuste son elementos esenciales para garantizar el éxito de la implementación de la IA en el ámbito empresarial.